Décrypter les graphiques
Découvrez comment il est possible de faire mentir des courbes en manipulant les échelles des graphiques. Apprenez à être attentif aux détails qui font toute la différence lorsque l’on visualise des données.
La crise sanitaire que nous traversons a engendré et accéléré la mise en place de tout un tas d’outils. L’un de ces outils, le plus puissant, est la collecte et le traitement d’informations liées à la propagation du Covid-19. Partout où le virus passe, il laisse derrière lui des données pouvant être utilisées pour le combattre.
Partout où le virus passe, il laisse derrière lui des données pouvant être utilisées pour le combattre. Ces données, une fois collectées, peuvent prendre plusieurs formes : le nombre de cas détectés, le nombre d’hospitalisations, le nombre de morts ou encore le nombre de lits disponibles dans les hôpitaux. Rien n’est gaspillé et toutes ces informations sont collectées puis envoyées dans des centres statistiques afin d’être traitées. En Belgique, c’est l’institut fédéral de santé publique Sciensano qui est chargé de centraliser ces données. Il est également chargé de publier régulièrement des rapports épidémiologiques à destination des décideurs politiques, des médias et des citoyens.
C’est en se basant, en partie, sur le contenu de ces rapports épidémiologiques que nos dirigeants décident des mesures sanitaires. En partant de ce postulat, on peut dire que nous sommes tous, en tant que citoyens, impactés par la collecte de données relatives à la propagation du coronavirus ainsi que par la façon dont elles sont mises en forme.
Des mesures justifiées par les données doivent pouvoir être vérifiable par les citoyens.Pierre Schaus, professeur en ingénierie informatique & co-fondateur de Covidata.be
La représentation la plus courante que prennent les données liées à la pandémie est une courbe. Cela s’explique assez simplement car la courbe est l’outil de visualisation de données le plus pertinent pour observer l’évolution d’un phénomène dans le temps. Et c’est bien de ça dont il est question ici : observer l’évolution de la situation sanitaire de très près afin de s’apercevoir du moindre changement pour réagir à temps et éviter les écueils. Les données du Covid-19 peuvent aussi être représentées à l’aide d’une carte. La visualisation cartographique est un outil très puissant permettant des visualisations statistiques réparties dans des zones géographiques. Il faut veiller à ne mobiliser cet outil que lorsque l’information que l’on souhaite présenter revêt déjà un caractère géographique.
Nous vivons désormais dans un monde où n’importe qui peut créer des graphiques à l’aide d’un ordinateur. Malheureusement tout le monde ne sait pas encore comment créer de bons graphiques, c'est-à-dire, des graphiques fidèles à l’information qu’ils sont censés transmettre.
Edward Tufte, décrit par le New York Times comme le Léonard de Vinci des données, propose une définition de “l’excellence graphique” dès 1990 :
"L’excellence graphique consiste à donner au lecteur la communication du plus grand nombre d’informations, dans le temps le plus court, dans l’espace le plus petit et avec le moins d’encre possible."
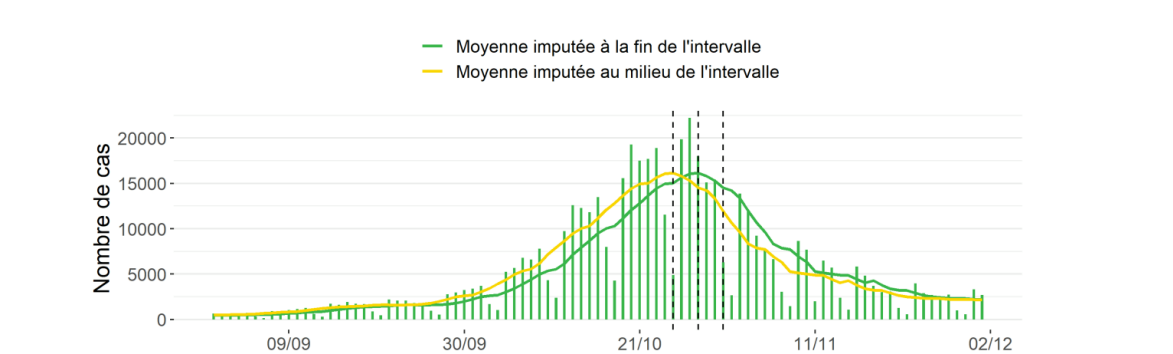
Dans l'exemple ci-dessous Catherine Hill, épidémiologiste à la retraite, est invitée sur le plateau de l'émission "24h Pujadas, l’info en question" de la chaîne LCI. Au bout de 3 minutes et 40 secondes de vidéo, l’experte réagit : “Mais tout le monde fait la moyenne sur sept jours. Donc il ne faut pas montrer ces trucs ou l’on voit un pic ! Et puis on compare le pic et le creux à l’intérieur d’une semaine... ce n’est pas sérieux comme façon de faire ! Il faut montrer les moyennes glissantes sur sept jours, c’est ce que font tous les professionnels”.
LES INDISPENSABLES 📌
— 24h Pujadas (@24hPujadas) February 2, 2021
▶️ #Covid19 – Les contaminations reculent partout, détail des indicateurs
Analyses et décryptages de @baptistemor1 dans Les Indispensables#24hPujadas #LCI #La26 ⤵️ pic.twitter.com/DbusjxqRN2
Comment être sûr d’avoir toutes les clés pour lire une courbe dans son contexte et bien la comprendre ? Heureusement, il existe des bonnes pratiques à respecter lors de la conception d’un graphique et vous pouvez commencer à y être attentif dès maintenant.
Un graphique est toujours composé de deux axes, l’axe des abscisses et l’axe des ordonnées (respectivement, X et Y). Et les paramètres que l’on va choisir d’appliquer à ces axes peuvent venir biaiser notre perception de l’information présentée.
Voyez l’exemple ci-dessous, le minimum et le maximum que l’on va choisir d'appliquer à l’échelle sur l’axe des ordonnées peuvent venir minimiser une tendance ou, à l’inverse, en donner une image exagérée :